We’ve worked with many customers to help them create microservice architectures. One pattern we’ve observed is that microservices sometimes take on a data engineering capability. When this happens, there’s a hidden data product, waiting to come to the fore.
With an established team already responsible for collecting and understanding the data, it can be a great starting point for an organisation new to data-driven decision making, and greatly empower capabilities such as Machine Learning.
What is a data product?
Just like a microservice, a data product is a domain-bounded, isolated product capability that provides value to its users. Unlike a microservice, the users of a data product interact with it in an ad-hoc manner, and there’s no specific set of user interactions.
A data product may be:
Surfaced through a business intelligence tool, for user generated reporting.
Combined by data scientists with other data products, to enable Machine Learning.
Brought into an operational data store, for real time usage by a microservice.
Leveraged by data engineers in a data pipeline to create new data products.
By extracting your data product, the owning team of the microservice can take responsibility for it and ensure it has the data engineering practices, data quality guarantees, and product ownership it needs. If a data product remains concealed within a microservice, users will struggle to leverage the data in a way that empowers the organisation.
Signs you’ve got a hidden data product
The following are some weak indicators of a hidden data product:
Users keep asking for more reports.
Direct requests for the data.
You can no longer process all the data in the application.
It’s a strong indicator if your microservice data is being used in a data pipeline. If it’s not being treated as a data product, it is probably fragile, lacking productionisation, and its development is being driven by microservice needs and not by other users of the data. This can look like:
Exports or replications of the data.
Users ask for more data sources to be added to enrich the data.
You spend most application development time handling data transformation.
One of these signals may not be cause enough for splitting out a data product, but a combination of them builds a very strong case!
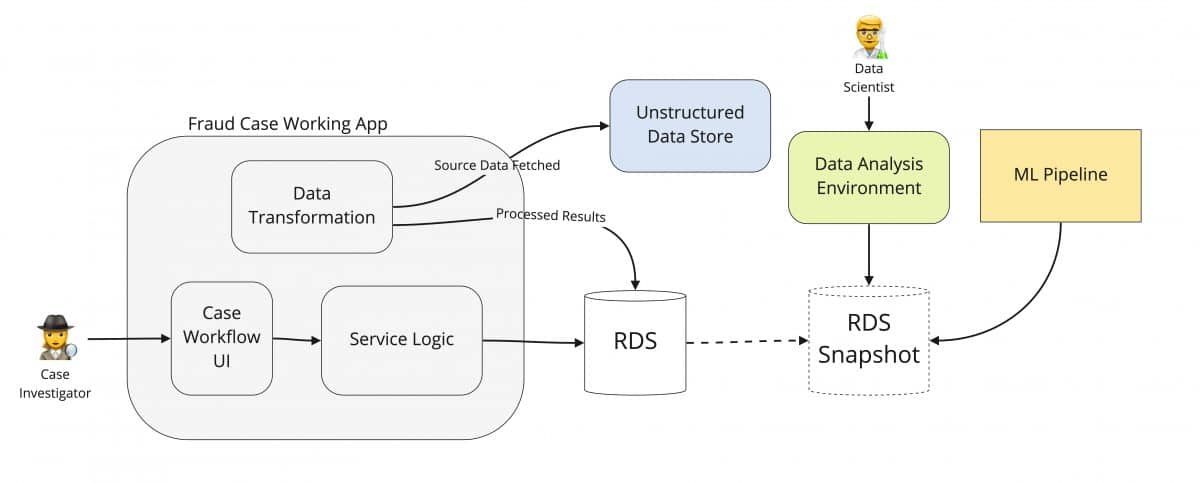
Example: Fraud case working application
A fintech company needs a way to protect and investigate potential fraudulent usages of its platform. To do so, they have created a case working tool for their fraud analysts that provides a summarised view across incoming transactions for quick assessment.
This data transformation logic takes place within the microservice, and is sourced from the raw unstructured data store.
The application naturally grew in size over time and several of our data product indicators are now present:
Data transformations inside the application constitute most of the engineering work, with users frequently asking for it to be extended.
The RDS store of summarised result data has been seen as very valuable by data scientists, and easier to work with than the raw semi-structured data, and a replica has been shared.
The RDS replica is now also used as the basis for a machine learning pipeline.
These signals all point to the data inside the case working application as being exceptionally valuable, and worthy of being a data product.
How to surface your data product
Start out by building a data pipeline for your data product, assuming it doesn’t exist already. We’ve got a Data Pipeline Playbook that can help you with this.
Your team may need to bring in some data engineering expertise, but the developers who own the relevant microservice will be able to pair with them, and promote a cross-discipline approach to implementing your new data product.
Aim for a steel thread implementation, and try surfacing it directly to analytical users for feedback. After that, start to integrate it back into your microservice, and replace the microservice code. This is an example of the popular Strangler Fig pattern for incremental design.
It’s important to remember that your microservice is no longer the sole driver of this data product, and that it may need to do its own transformation of the data, so as not to disrupt other consumers of your new data product.
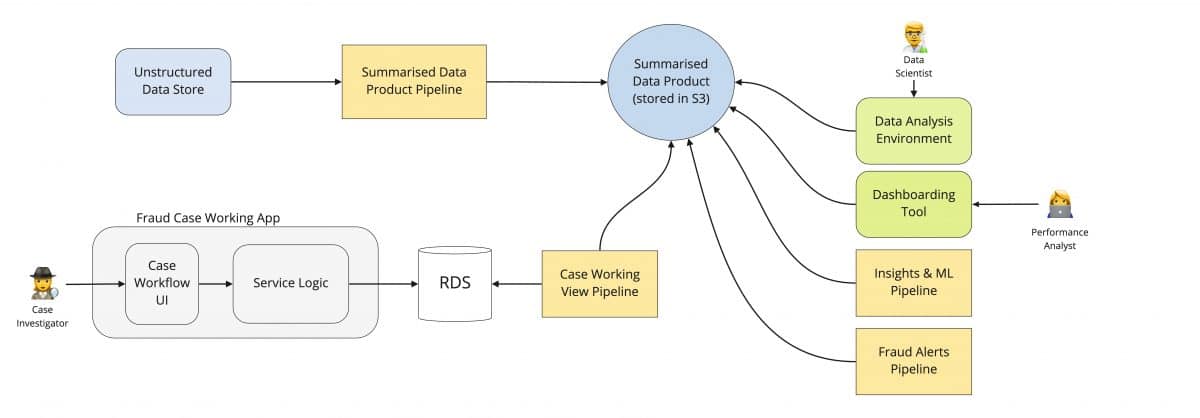
Example: Fraud case working application
Back to the project team at our fintech. Now aware of the value of the summarised data in the case working app, they have taken the steps of separating it into its own data pipeline, running on the AWS EMR/Spark stack.
This has provided multiple benefits:
The footprint of the application is significantly reduced.
The data product is now leveraged not only by data scientists, but also other users such as performance analysts, giving them a cleaner data set to work with.
Other data products have begun to leverage the summarised data set beyond initial plans, in this case a growing product for analytical insights and fraud alerts.
Data enrichment, data quality, validation tests, and versioning management can all be managed around the data product itself.
They can now process much more data and extend its historical accuracy by moving it to a purpose built tool in Spark.
A lot of inspiration and central concepts for this blog come from the Data Mesh Architecture proposed by Zhamek Dhegani.
We wish your new Data Product the best of luck on its journey!
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.