It is common to hear that ‘data is the new oil,’ and whether you agree or not, there is certainly a lot of untapped value in much of the data that organisations hold.
Data is like oil in another way – it flows through pipelines. A data pipeline ensures the efficient flow of data from one location to the other. A good pipeline allows your organisation to integrate new data sources faster, provide patterns that you can replicate, gives you confidence in your data quality, and builds in security. But, data flow can be precarious and, when not given the correct attention, it can quickly overwhelm your organisation. Data can leak, become corrupted, and hit bottlenecks and, as the complexity of the requirements grow, and the number of data sources multiplies, these problems increase in scale and impact.
About this series
This is part one in our six part series on the data pipeline, taken from our latest playbook. Here we look at the very basics – what is a data pipeline and who is it used by? Before we get into the details, we just want to cover off what’s coming in the rest of the series. In part two, we look at the six main benefits of a good data pipeline, part three considers the ‘must have’ key principles of data pipeline projects, and parts four and five cover the essential practices of a data pipeline. Finally, in part six we look at the many pitfalls you can encounter in a data pipeline project.
Why is a data pipeline critical to your organisation?
There is a lot of untapped value in the data that your organisation holds. Data that is critical if you take data analysis seriously. Put to good use, data can identify valuable business insights on your customers and your operations. However, to find these insights, the data has to be regularly, or even continuously, transported from the place where it is generated to a place where it can be analysed.
A data pipeline, consolidates data from all your disparate sources into one (or multiple) destinations, to enable quick data analysis. It also ensures consistent data quality, which is absolutely crucial for reliable business insights.
So what is a data pipeline?
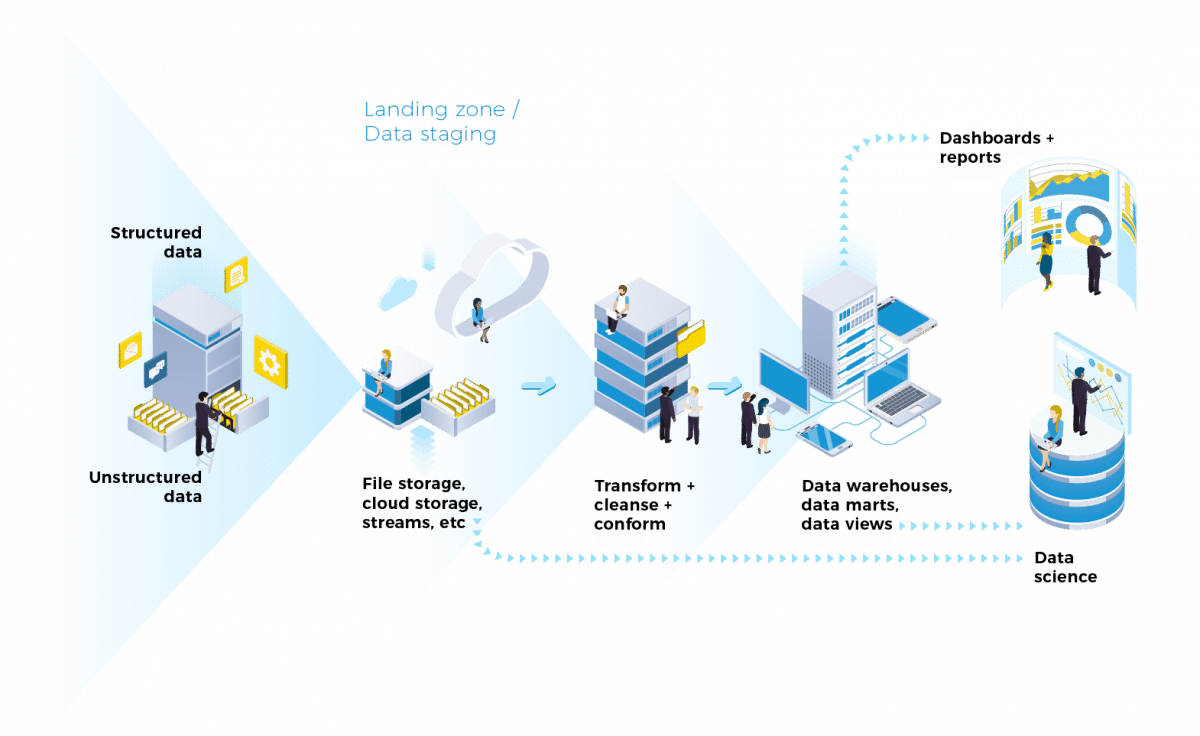
A data pipeline is a set of actions that ingest raw data from disparate sources and move the data to a destination for storage and analysis. We like to think of this transportation as a pipeline because data goes in at one end and comes out at another location (or several others). The volume and speed of the data are limited by the type of pipe you are using and pipes can leak – meaning you can lose data if you don’t take care of them.
The data engineers who create a pipeline are a critical service for any organisation. They create the architectures that allow the data to flow to the data scientists and business intelligence teams, who generate the insight that leads to business value.
A data pipeline is created for data analytics purposes and has:
Data sources – These can be internal or external and may be structured (e.g., the result of a database call), semi-structured (e.g., a CSV file or a Google Sheets file), or unstructured (e.g., text documents or images).
Ingestion process – This is the means by which data is moved from the source into the pipeline (e.g., API call, secure file transfer).
Transformations – In most cases, data needs to be transformed from the input format of the raw data, to the one in which it is stored. There may be several transformations in a pipeline.
Data quality/cleansing – Data is checked for quality at various points in the pipeline. Data quality will typically include at least validation of data types and format, as well as conforming with the master data.
Enrichment – Data items may be enriched by adding additional fields, such as reference data.
Storage – Data is stored at various points in the pipeline, usually at least the landing zone and a structured store (such as a data warehouse).
End users – more information on this is in the next section.
So, who uses a data pipeline?
We believe that, as in any software development project, a pipeline will only be successful if you understand the needs of the users.
Not everyone uses data in the same way. For a data pipeline, the users are typically:
Business intelligence/management information analysts, who need data to create reports;
Data scientists who need data to do an in-depth analysis of point problems or create algorithms for key business processes (we use ‘data scientist’ in the broadest sense, including credit risk analysts, website analytics experts, etc.)
Process owners, who need to monitor how their processes are performing and troubleshoot when there are problems.
Data users are skilled at visualising and telling stories with data, identifying patterns, or understanding significance in data. Often they have strong statistical or mathematical backgrounds. And, in most cases, they are accustomed to having data provided in a structured form – ideally denormalised – so that it is easy to understand the meaning of an individual row of data without the need to query separate tables or databases.
Is a data pipeline a platform?
Every organisation would benefit from a place where they can collect and analyse data from different parts of the business. Historically, this has often been met by a data platform, a centralised data store where useful data is collected and made available to approved people.
But, whether they like it or not, most organisations are, in fact, a dynamic mesh of data connections which need to be continually maintained and updated. Following a single platform pattern often leads to a central data engineering team tasked with implementing data flows.
The complexities of meeting everyone’s needs and ensuring appropriate information governance, as well as a lack of self-service, often make it hard to ingest new data sources. This can then lead to backlog buildup, frustrated data users, and frustrated data engineers.
Thinking of these dataflows as a pipeline changes the mindset away from monolithic solutions, to a more decentralised way of thinking – understanding what pipes and data stores you need and implementing them the right way for that case whilst reusing where appropriate.
So now we have understood a little more about the data pipeline, what it is and how it works, we can start to understand the benefits and assess whether they align with your digital strategy. We cover these in the next blog article, ‘What are the benefits of data pipelines?’
For more information on the data pipeline in general, take a look at our Data Pipeline Playbook. And if you’d like us to share our experience of the data pipeline with you, get in touch using the form below.
You may also like
Blog
Anyone Can Usability Test, Part 3: Making the Most of Your Findings
Blog
Do we need roles in a cross functional team?
Blog
It’s the difference between ‘doing agile’ and ‘being agile’
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.