Escape ticketing hell with a shift to self-service platforms
Platform engineering creates user-centric capabilities that enable teams to achieve their business outcomes faster than ever before. At Equal Experts, we’ve been doing platform engineering for over a decade, and we know it can be an effective solution to many scaling problems.
Unfortunately, it’s easy to get platform engineering wrong. In this series, I’m covering some of its pitfalls. First, it was the power tools problem, then the technology anarchy problem, and today it’s the ticketing hell problem.
Fewer handoffs, more speed
A platform engineering team aims to accelerate technology outcomes for all their teams, so they can deliver business outcomes faster than ever. I’ve explained before how those technology outcomes map onto the DORA metrics:
Speed (deploy lead time and deploy frequency)
Quality (unplanned tech work)
Reliability (deploy fail rate and time to restore)
At Equal Experts, we define engineering excellence as achieving high standards in all these metrics. One of the main blockers to excellence is handoffs. They occur when a team depends on another to complete a task, such as needing DBAs for schema creation, change managers for approvals, or your operations team for deployments. If you have handoffs in platform engineering, your teams will be stuck in ticketing hell.
The nightmare of ticketing hell
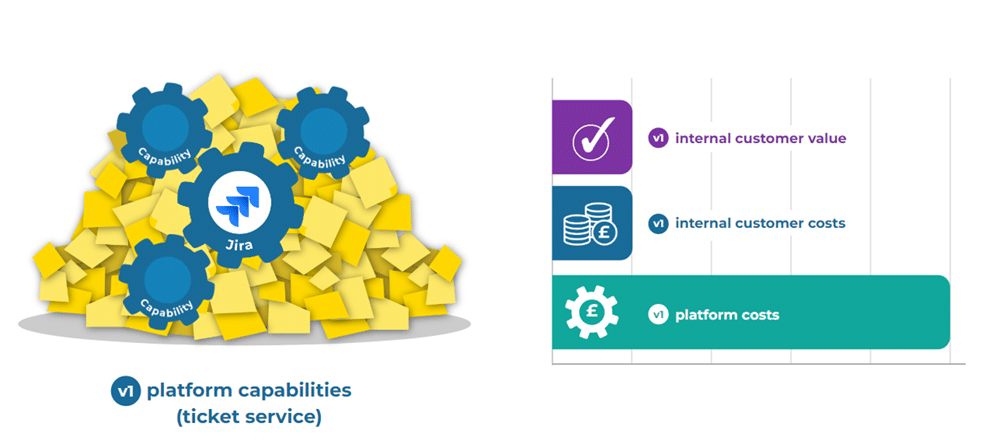
Ticket-driven platform capabilities can seem appealing. Your platform team can reuse existing workflows, and teams can simply file a ticket when they need something. However, this approach causes delays, as tasks are stuck in different queues e.g. triage, priorized, blocked. A task to create, deploy, or restart a service might take minutes to complete, but the queue beforehand can take days or weeks.
You can measure a platform capability in internal customer value, internal customer costs, and platform costs. Here’s a v1 platform with ticket-driven capabilities, and it’s a long way from our high value, low cost ideal:
Internal customer value is low. Technology outcomes can’t be significantly accelerated for teams, because there are so many handoffs and queue delays
Internal customer cost is low. Fortunately, teams don’t have much unplanned tech work, because everything is handled by the platform team
Platform costs are high. The platform team has to manage a lot of incoming tickets from teams, on top of actual build and run work for the platform
This pitfall happens when your organization has a long-term, ITIL-driven culture of centralized workflow management. Platform team workload will grow uncontrollably as you increase teams and platform capabilities. Ticket queues, conflicting priorities, and strained relationships will damage speed, quality, and reliability for your teams.
For example, at a Dutch bank we saw a new employee wait 11 weeks for access to code repositories, because their request was stuck in the platform team’s queue. The employee felt unproductive, but they were reassured by their team it was standard practice.
And at an Australian telco, any deployment to any environment requires a platform ticket, which creates a combinatorial explosion. The platform team can’t keep up with demand, which results in blocked deployments, prioritization clashes, and platform engineer burnout.
Embracing the power of self-service
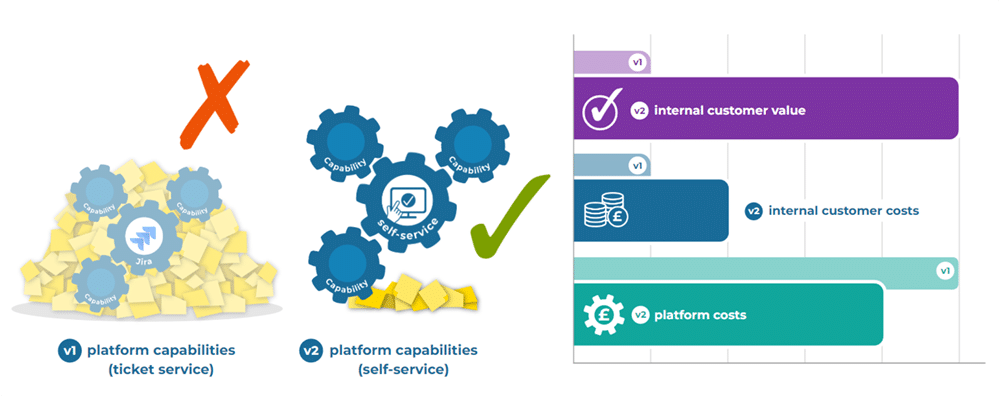
The wrong answer to ticketing hell is to embed platform engineers into teams, as it’s unsustainable and creates its own problems. The right answer is to standardize on self-service workflows with automated guard rails and audit trails. Here’s how your platform team can get started:
Measure the end-to-end time for all v1 ticket workflows.
Prioritize a task that’s frequently used, and frequently slow for teams.
Create a v2 self-service, fully automated pipeline that consistently performs the task to a high standard, and logs an entry in an audit trail afterwards.
Visualize the audit trail in a platform portal, so teams and their stakeholders can understand the impact of their actions on user behaviors.
Migrate teams from the v1 workflow to the v2 solution for a single task, delete the v1 workflow.
Move onto the next priority workflow.
Here’s v2 of that imaginary platform. There’s a much higher internal customer value for teams when they’re able to move quickly and meet business demand. Your platform engineering efforts can be shown to have accelerated outcomes.
Conclusion
Ticketing hell can cripple your platform engineering efforts by creating bottlenecks and frustration. By transitioning to self-service capabilities, you can unlock higher internal customer value and empower your teams to deliver business outcomes
I’m going to be sharing more platform engineering insights in my talk “Three ways you’re screwing up platform engineering and how to fix it” at the Enterprise Technology Leadership Summit Las Vegas on 20 August 2024. If you’re attending, I’d love to connect and discuss platform engineering challenges and solutions.
You may also like
Blog
Anyone Can Usability Test, Part 3: Making the Most of Your Findings
Blog
Do we need roles in a cross functional team?
Blog
It’s the difference between ‘doing agile’ and ‘being agile’
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.