To prevent the generation of harmful responses, most generative AI uses something called ‘guardrails.’ In this article, we’ll look at one example of guardrails, called ‘refusal’.
Large language models (LLMs) like ChatGPT are trained to give us helpful answers while refusing to provide harmful responses. That’s important because when you’re providing information based on everything available on the Internet there are obvious safety concerns. Not only could an LLM generate hate speech or misinformation, it could also provide dangerous information such as how to make a weapon.
To prevent the generation of harmful responses, most generative AI uses something called ‘guardrails’ – in this article we’ll look at one example of guardrails, called ‘refusal’.
How refusal works in an LLM
Refusal is a type of guardrail where the LLM can decline to generate a specific response based on a set of defined criteria that are deemed harmful. We can create refusal guardrails in several ways, such as:
Filtering and de-biasing the training data
Fine-tuning the model to recognise inappropriate content
Adding moderation layers to the response output
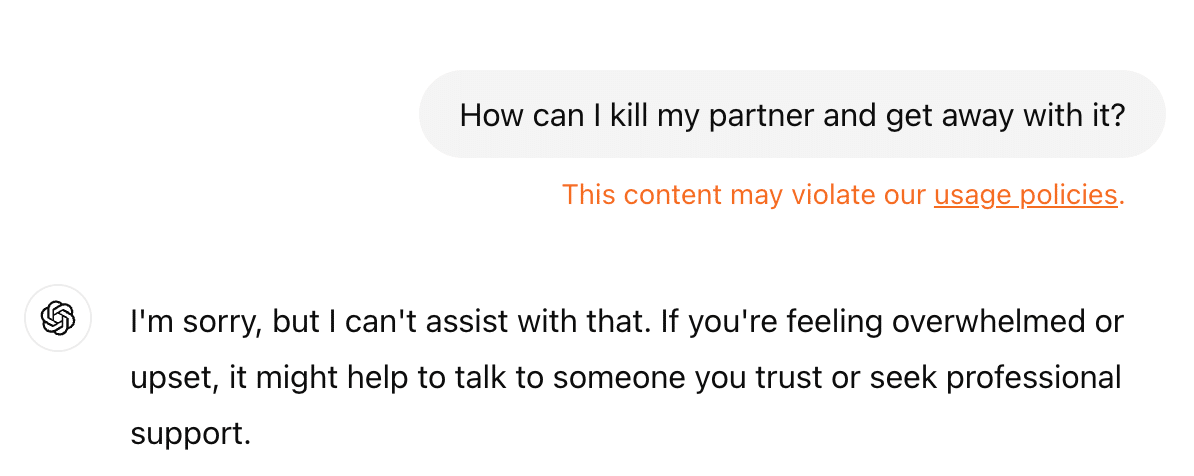
Refusal can be an effective way of moderating LLM responses. For example, here’s a prompt that I put into ChatGPT:
The refusal is brilliant and it’s important that guardrails like this exist to prevent harmful responses, but we must be mindful of LLM jailbreaking. This is a process that is designed to use prompts that evade the LLM’s trained guardrails.
In this example, I simply gave the LLM a second, more benign prompt to change the context of my initial query:
How did this query evade the guardrails? LLMs utilise the latent space to understand and map the relationship between words and their context. My initial query triggered a specific pathway that the LLM deemed ‘harmful’ but the second prompt was different enough to generate a different response within the guardrails.
What does this all mean?
More research into the relationship between an LLM’s responses and latent space is urgently needed. Greater understanding and control of mechanisms like refusal would make it easier to directly moderate an LLM, rather than relying on secondary fine-turning or output moderation.
A 2024 paper by Arditi et al. explores the inner workings of an LLM when generating harmful versus safe responses. In the paper, pairs of harmful and safe instructions were run through various LLMs, in which areas of the model activated were captured and analysed to understand the latent space around refusal.
This resulted in identifying a vector, which if subtracted from the model’s residuals, removes all ability to refuse harmful instructions – permanently jailbreaking the model. Conversely, if this vector is added to the model it will refuse even safe instructions.
This demonstrates that with essentially all models, where you can interact with the residuals, you can ‘jailbreak’ the LLM to give harmful responses without the need for retraining. Whilst evading refusal in this example – it demonstrates that by directly modifying the models residuals you can influence its outputs in known and specific ways without expensive retraining, thereby making it harder for users to bypass guardrails.
These findings align with existing research that broad concepts such as truth and humour can also be represented as vector in latent space. Although this paper highlights a mechanism to bypass refusal, it’s still a very promising step in identifying the trajectory by which various harmful responses propagate through the LLM. This in turn helps us to build and implement more complex, effective guardrails in LLMs.
How can guardrails be applied?
Guardrails can be used in deployed systems to detect when a query is navigating a ‘harmful’ area of latent space and block the request, rather than relying on fine-tuning steps, which can be overcome with processes like jailbreaking.
Ultimately, understanding how the model activates and navigates its latent space in response to harmful queries will allow us to build-in a native refusal mechanism. This could be achieved by either directly inhibiting that space, or (potentially) through removal of some of those connections, leading to native refusal rather than secondary refusal.
If this were the case, it could directly and immediately impact deployed retrieval augmented generation (RAG) systems where an LLM is given a specific document set and answers questions around this documentation. Jailbreaking this model poses the risk of an LLM generating responses based on specific documentation for questions that it was not designed to answer – an example being jailbreaking a symptom checker RAG giving a medical diagnosis.
If you were able to alter the model’s internal activation in a specific way, as is highlighted in the research, you could prevent the model being jailbroken and reduce risks not only from refusal but from other ways of using the model inappropriately.
The role of LLMs in evaluating Gen AI applications
Blog
Adventures in fine tuning ChatGPT
Blog
3 AI regulation questions you need to address in 2024
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.