Engineering GenAI systems: A systematic approach through healthcare documentation (Part 2)
“Look how well it extracted the patient’s history!”
The physician’s enthusiasm was palpable as they reviewed our initial prototype. At that moment, I witnessed a common pattern in enterprise AI implementations: the seductive power of early demos overshadowing the engineering rigour needed for production systems. While our proof-of-concept (discussed in Part 1) demonstrated the foundational capability of large language models to parse clinical conversations, the path from a promising demo to a production-ready system requires sophisticated validation infrastructure.
Continuing the systematic approach from Part 1, we now face a core engineering task: building an evaluation framework robust enough to stress-test our solution across diverse clinical scenarios. Each variation introduces potential failure modes that must be systematically validated, from edge cases in medical terminology to speciality-specific documentation patterns.
Our evaluation framework comprises 3 components: Golden datasets that accurately represent the diversity and complexity of real-world clinical documentation; Comprehensive metrics that quantify technical and clinical quality aspects; and Evaluations, often called Evals, which validate system behaviour.
Let’s see how these components work together in practice.
Building a golden dataset for SOAP note generation
At the core of any robust evaluation framework lies the golden dataset — a curated collection of inputs and their corresponding reference outputs that serves as ground truth for system validation. While the concept sounds straightforward, creating a reliable golden dataset often reveals a complex interplay between theoretical requirements and practical constraints.
In our medical documentation system, we identified a solid foundation: a diverse set of patient-doctor dialogues. However, the critical missing piece was the corresponding reference SOAP notes — the “gold standard” outputs that would validate our system’s performance — generating these reference notes required (again) collaboration with a physician due to the domain expertise needed.
Rather than pursuing the traditional (and time-intensive) route of manual annotation, I developed a hybrid approach that leveraged AI capabilities. I used a simple crafted prompt to generate initial SOAP notes drafts:
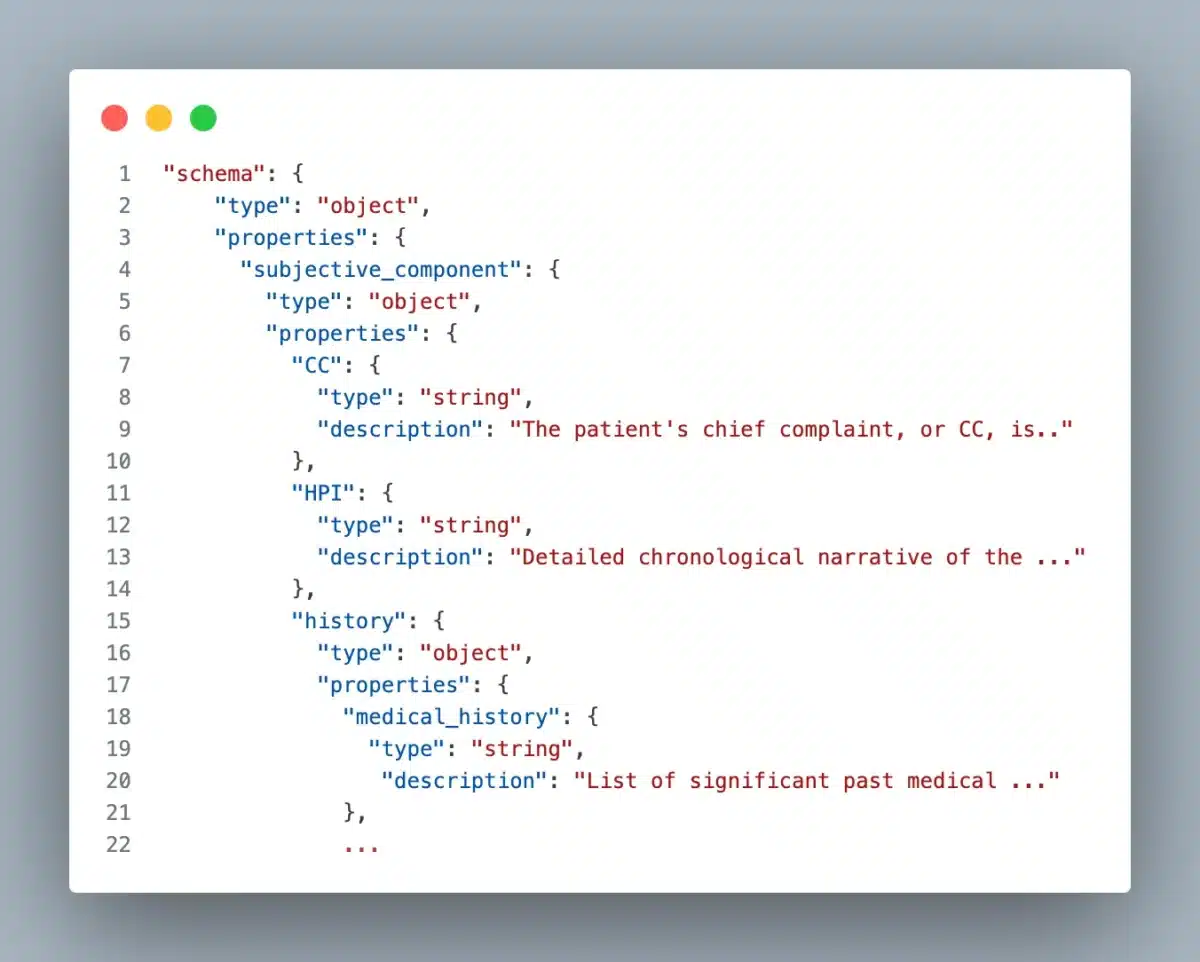
combined with a structured JSON schema:
for LLM output formatting (using structured outputs from OpenAI), provided a low-effort starting point for physician review.
While production systems typically demand hundreds of validated examples, we strategically limited our initial dataset to 25 entries for the sake of my exploration. However, even with this concentrated scope, we maintained rigorous selection criteria:
Representational diversity: Included varied dialogue patterns and medical conditions to stress-test the system’s adaptability
Edge case coverage: Deliberately incorporated complex scenarios that challenge common assumptions
The process revealed why golden datasets, despite their critical importance, often become a bottleneck in AI system development. They demand a rare combination of domain expertise, technical precision, and substantial time investment — it took a few hours to review the 25 entries, even with the synthetic drafts. Yet, this foundation proves invaluable when scaling systems from promising prototypes to production-ready solutions.
This golden dataset would serve multiple critical functions in our use case. The question became: how do we leverage this carefully curated foundation to build a comprehensive evaluation framework? This leads us to our next challenge: implementing systematic evaluation strategies.
Evals
Evals are fundamentally tests, but they represent an evolution in testing methodology driven by the unique challenges of LLM-based systems. While traditional software tests verify deterministic behaviours against fixed expectations, Evals handle language model outputs’ inherent variability and contextual nature. There are two types of evals:
Deterministic Evals: these provide unambiguous pass/fail signals for structured fields:
Boolean fields (smoking status, drug use)
Enumerated values (alcohol consumption frequency)
Required field presence
Format compliance
Non-Deterministic Evals: these address qualitative aspects requiring nuanced assessment:
Semantic accuracy of chief complaints
Completeness of medical histories
While deterministic evals are similar to common tests, non-deterministic evals require us to define the criteria for evaluation, usually composed of a few metrics. Continuing in our example, we identified 3 metrics as a starting point:
Completeness: Measures whether all the clinical information is present regardless of the order or the way it’s described
Accuracy: All the present information should match the reference
No hallucination: Restating/rephrasing existing information is acceptable, but the inference of a plan, such as a diagnosis, should not happen.
Taking this into account, we can jump into the implementation.
Practical deep dive
For practical implementation, I leveraged promptfoo, an open-source framework that brings software engineering rigour to prompt evaluation to illustrate how evals could look in practice.
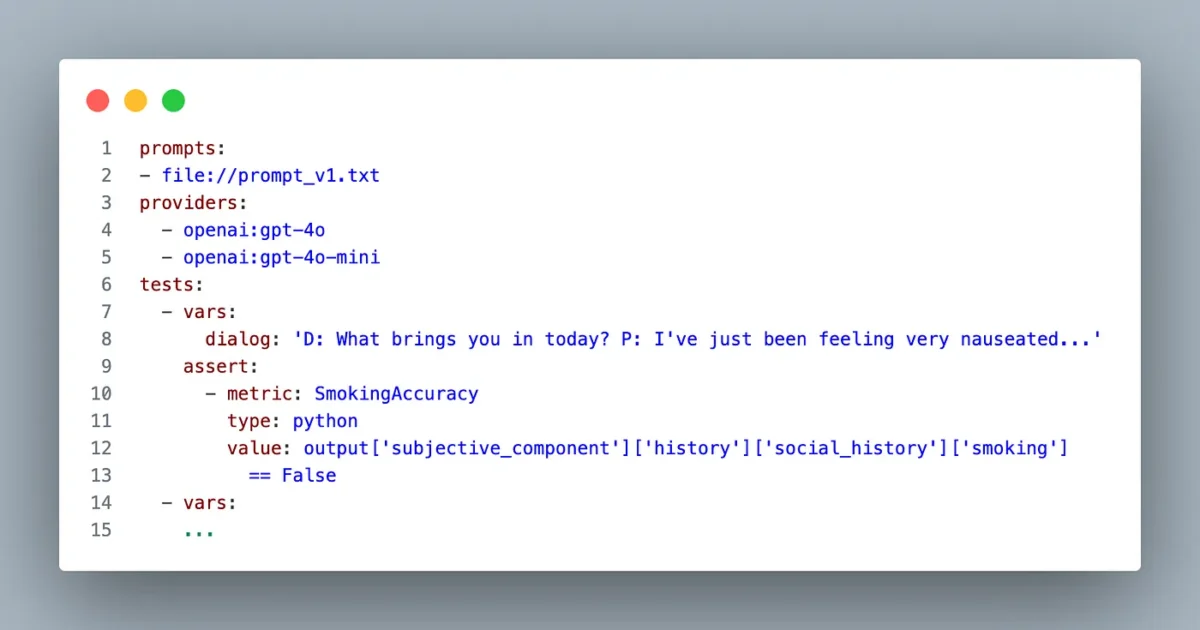
Here’s a concrete example of how we can structure a non-deterministic test:
In the section prompts, we can declare one or more prompts to be evaluated; as for the section providers, we can declare one or two providers to be evaluated. The tests section contains multiple tests, and each test is composed of vars (input variables) and asserts that compare the output with the reference. Promptfoo has many types of assertions, and for this specific example, I’m using a Python assert where I can pass the assertion as Python code.
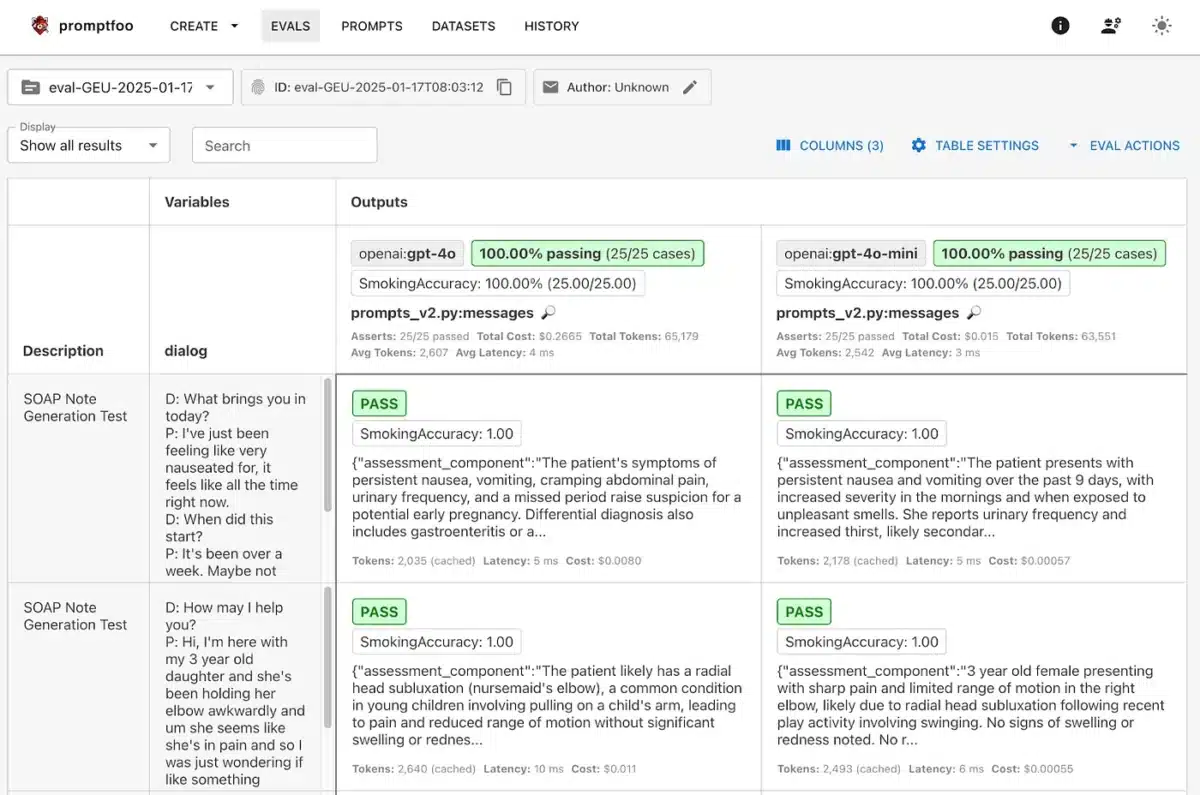
To create the config file for the golden dataset, I created a script that generates the YAML config based on the golden dataset (meaning having 25 tests like the previous one, one for each entry). With the config file in place, we can run the prompt and get the following results:
For this particular case, the initial prompt behaves quite well in both GPT-4o and GPT-4o-mini for the smoking field. Implementing the missing deterministic tests is straightforward now.
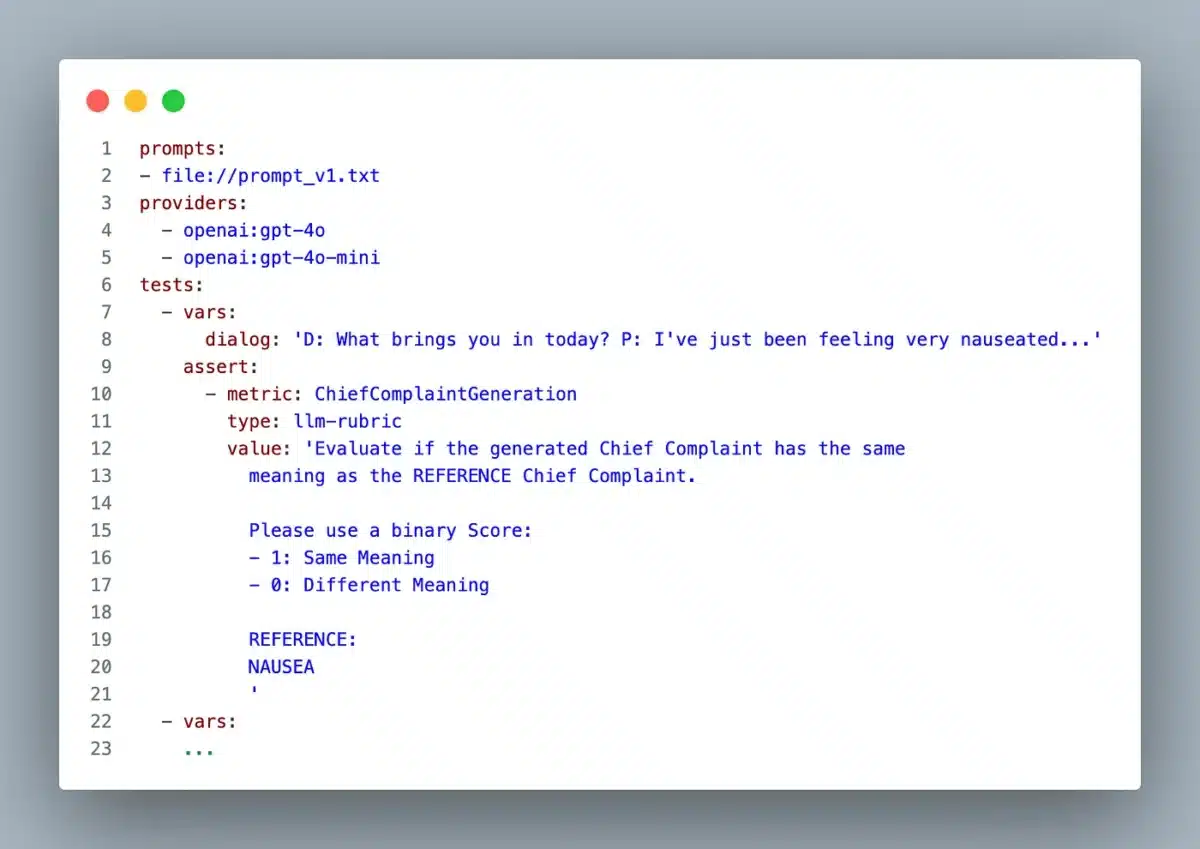
For the non-deterministic tests, we will use a model-graded assert from promptfoo that allows us to pass a rubric prompt where we can describe how a reference field should be evaluated against a generated field.
While promptfoo streamlines our evaluation process by running a rubric using GPT-4o as the default model evaluator, this introduces an interesting technical paradox: how do we validate the validator? Using a non-deterministic language model to evaluate another language model’s output creates a potential blind spot in our evaluation framework.
The solution emerges from applying recursive validation patterns — a common approach in complex system verification. As we validate our SOAP note generation, we must systematically validate our rubric prompt.
This requires creating a secondary golden dataset specifically for evaluating our rubric prompts:
Coverage: Diverse scenarios, including edge cases and boundary conditions
Since our rubric returns a binary value, we can evaluate it with deterministic tests.
After crafting the golden dataset and the tests in promptfoo, the first iteration of the rubric prompt revealed gaps in evaluation coverage. Critical aspects of medical documentation quality weren’t being captured consistently, and there were a few hallucinations. This led to a comprehensive redesign of the rubric by taking into consideration the metrics shown above, resulting in the following structured rubric:
Which worked flawlessly in the (small) rubric golden dataset.
This experience reinforces a crucial lesson in AI system development: evaluation frameworks themselves must evolve through iterative refinement, guided by concrete validation metrics (deterministic if possible) and real-world usage patterns.
The reality check
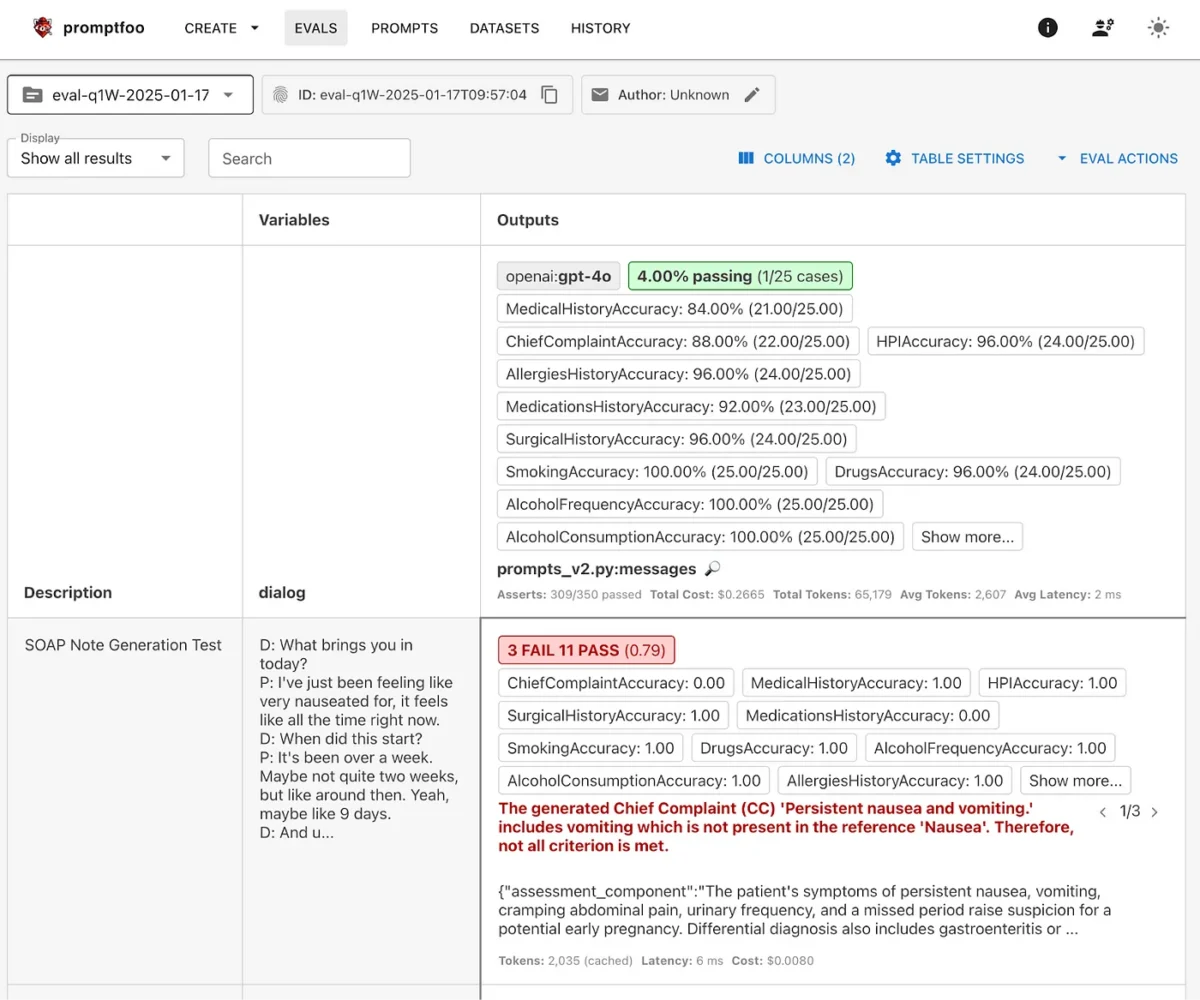
We now have all the tools we need to create the evals for our initial use case: we have the golden dataset, we know how to do deterministic evals and non-deterministic evals, and last but not least, we have a degree of trust in our deterministic evals. To do this, I created a Python script that outputs a promptfoo config file with all the testing scenarios for all the golden dataset records. This is the result of running it with our current implementation described above:
Running our evaluation framework across the 25-case dataset provided good insights: only one SOAP note passed all evaluation criteria, although 309 out of 350 tests passed. While initially disappointing, this outcome offers valuable lessons about the complexity of medical documentation and the importance of comprehensive evaluation.
This result doesn’t indicate failure — rather, it demonstrates the value of rigorous evaluation in surfacing areas requiring refinement. Each failing test provides specific, actionable feedback for improving our system’s reliability.
Engineering insights and trade-offs
Through implementing this evaluation framework for SOAP note generation, several key architectural decisions emerged that warrant deeper examination. Let’s explore the trade-offs and practical implications of these choices.
Golden datasets as living rrtifacts
While our initial golden dataset provides a foundation for development and validation, production environments demand an evolutionary approach. Golden datasets must function as living artefacts that grow and adapt alongside the system they validate (e.g. incorporate new edge cases).
Granularity of evaluations
Evaluating SOAP notes field-by-field rather than as complete documents proved instrumental in managing system complexity. This approach delivers clearer error signals and enables targeted improvements for specific components. However, it introduces significant computational overhead — our modest golden dataset of 25 cases spawned 350 distinct tests, with most requiring LLM inference for evaluation. While this granularity provides excellent debugging capabilities during development, it raises important considerations for production scaling.
Rubric design strategy
The rubric prompt unified key metrics (completeness, accuracy, hallucination, format compliance) into one rubric. While this consolidated approach served well for initial validation with our limited dataset, production deployment would benefit from decomposition into separate rubric evaluations. This separation would enable:
More precise performance monitoring
Targeted optimisation of specific quality dimensions
Clearer attribution of failure modes
Enhanced maintainability of evaluation logic
Rubric score
The decision to implement binary scoring (1/0) for our rubric evaluations, rather than nuanced scoring scales, emerged from lessons in production AI systems. This approach might seem reductionist at first glance. Still, it delivers several critical advantages: deterministic decision boundaries (making it easy to evaluate the rubric), easier to create the rubric golden dataset and minimises subjective interpretations.
Evals cost
Running evals at scale introduces non-trivial operational costs that demand strategic consideration. Our small golden dataset already incurs several euros per run — a cost that multiplies significantly with larger datasets and continuous integration pipelines. Practical mitigation strategies include implementing staged evaluations (not every change requires full validation) and deploying dedicated infrastructure. These architectural decisions become crucial for maintaining system reliability and operational efficiency at scale.
Moving forward
Our evaluation framework has provided clear visibility into current system performance. With only one SOAP note passing a full evaluation, we have a data-driven foundation for systematic improvement. The path forward involves targeted refinements across multiple dimensions:
Prompt engineering evolution
The (intentional) simple baseline prompt is a starting point rather than a final solution. With our evaluation framework in place, we can now:
Systematically test prompt variations (few-shot prompting, chain-of-thought reasoning, structured guidance)
Measure specific impact on evaluation metrics
Architectural refinement
If prompt engineering alone proves insufficient, the next step is considering decomposition into specialised components:
Breaking SOAP generation into discrete, independent stages
Implementing targeted models for high-complexity sections (e.g. for the smoking field, GPT-4o-mini revealed good enough, but for complex sections, a strong model is needed)
Building feedback loops (self-reflection / output refining)
The key insight here isn’t just about improving accuracy — it’s about building systems that evolve systematically based on quantifiable metrics. Our evaluation framework now enables this disciplined, evidence-based approach to production readiness.
You may also like
Blog
Engineering GenAI systems: A systematic approach through healthcare documentation (Part 1)
Blog
6 reasons GenAI Pilots fail to move into production
Blog
How businesses can move GenAI projects from proof-of-concept to production
Get in touch
Solving a complex business problem? You need experts by your side.
All business models have their pros and cons. But, when you consider the type of problems we help our clients to solve at Equal Experts, it’s worth thinking about the level of experience and the best consultancy approach to solve them.
If you’d like to find out more about working with us – get in touch. We’d love to hear from you.